LAnoBERT System Log Anomaly Detection based on BERT Masked Language Model (Reading note)
LAnoBERT : System Log Anomaly Detection based on BERT Masked Language Model (Reading note)
0. Abstract
previous problem
- Solving problem :system log anomaly detection
- Previous studies : standardized -> anomaly detection
- Issues : template corresponding -> log key losting
LAnoBERT
- parser free system log anomaly detection method
- BERT model : natural language processing
- masked language modeling : BERTbased pre-training method
- test process : unsupervised learning-based anomaly detection using the masked language modeling loss function per log key
- efficient inference process : pipeline to the actual system
Dataset
- log datasets : HDFS, BGL, and Thunderbird
- performance :
- higher anomaly detection performance compared to unsupervised learning-based benchmark models
- comparable performance with supervised learning-based benchmark models
1. Introduction
- minimizes human intervention
- Log data : sequence data + many duplicates + single log sequence is short
Machine learning-based log anomaly detection :
drawback of traditional studies
- Reliance on Log Parsers : requires predefined templates for standardizing log keys
- Feature embedding with rich semantics for longterm dependency : RNN bad at long consequence & transformer-based better in natural language processing
- Unrealistic problem formulation : problem regarded binary classification instead of anomaly detection & realistic small amount of abnormal logs
solutions and improvement
solutions :
- Regular expressions to mitigate information loss and to minimize dependence on a specific log parser
- BERT model extract Contextualized embedding :
- unsupervised learning-based anomaly detection
improvement :
- a new BERT-based unsupervised and log parser-free anomaly detection framework for log data
- an inference process utilizing a log dictionary database is proposed to identify abnormal logs (efficient improvement)
- demonstrated better or comparable performance to supervised learning-based models
2. Related Work
Log anomaly detection preprocessing method: parsing-based or parsing-free
parsing-based:
Study 1: Drain Parser
- Method: Uses Drain parser for log classification and template allocation.
- Model: DeepLog employs LSTM for unsupervised anomaly detection.
- Limitations: Requires domain expertise and candidate selection affects performance.
Study 2: LogRobust
- Method: Deploys attention-based bi-LSTM model with Drain parser preprocessing.
- Model: Classification-based for anomaly detection.
- Limitations: Relies on a parser and classification approach.
Study 3: HitAnomaly
- Method: Utilizes Transformer for anomaly detection with Drain parser preprocessing.
- Model: Employs attention-based encoding for classification-based anomaly detection.
- Limitations: Depends on a parser and follows a classification approach.
Study 4: LogBERT
- Method: BERT-based log anomaly detection, refining log sequences with Drain parser.
- Model: Uses masking and sphere volume minimization for inference, but doesn’t fully consider the entire log sequence.
- Limitations: Still relies on masking and doesn’t fully capture log sequence.
Our Study
- Method: Proposes log anomaly detection independent of log parser, using simple preprocessing.
- Model: Employs mask-based BERT for effective anomaly detection across various log types.
- Advantages: Parser independence, minimized information loss, and comparable performance to supervised learning models.
parsing-free
- LogSy: A transformer-based anomaly detection model that doesn’t rely on log parsers. Uses a tokenizer for preprocessing and classification. Trains to increase the distance between normal and abnormal data.
- NeuralLog: Another parser-free, classification-based model similar to LogSy but utilizes data from both the target system and a separate system during training.
- Proposed Model: Also parser-free. After simple preprocessing, log sequences are tokenized and used directly for anomaly detection. Offers flexibility for new log sequences.
3. Background
Log parser for anomaly detection
- purpose : unstructured data must be converted to structured data
- process : complicated data are preprocessed for substitution with very few events
- example : 4,747,964 log messages converted to 376 events —Drain parser (He et al., 2017)
BERT
- BERT (Devlin et al., 2019) is a model consisting of a transformer (Vaswani et al., 2017) encoder
- natural language processing tasks
- major characteristics(pre-training using two unsupervised learning methods) :
- masked language modeling (MLM) : replace token to “[MASK]”
- next sentence prediction (NSP) : combining two sentences “[SEP]” in front “[CLS]”
- DataSet(do not require labeled data) : (Clark et al., 2019; Jawahar et al., 2019; Tenney et al., 2019).
BERT for anomaly detection
- system log -> dataset with order (log messages and natural language)
limitations and Solutions :
Data processing:
- Previous methodologies treated all log data as sequence data
- BERT enables the learning of both the log features and natural language
parsing:
- tokenizer of BERT can be applied
- no need using a separate log parser (lose natural language)
semantics and context of the system log:
- words appearing in the system log may have a different meaning from natural language
- goal : an effective pre-training approach for the system log utilizing masked language modeling in a bi-directional context
matching technique :
- novel framework : trained models’ MLM loss and predictive probability -> identifying context anomalies
- inference stage : log key matching technique
4.Proposed Method
4.1 Masked Language Model
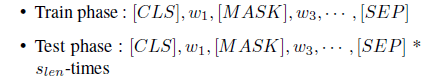
reasons for usingMLMin system log anomaly detection:
large amount of normal log data -> obtain numerous contextual and structural features during pre-training -> improve the generalization performance
MLM does not require the labeling of tasks -> only normal data are used for training -> better than supervised binary classification-based
appropriate methodology for prompt-based learning -> no require layers conforming to tasks to perform downstream tasks -> detection by comparing the actual log keys and the generated log keys
context of abnormal log data can be identified -> probability of certain words appearing varies if the context of surrounding words is considered
For example, let’s consider a sentence in normal log data: “Server startup successful.” In this sentence, the appearance of words like “Server” and “successful” is considered normal because they typically appear in this context. However, if the same words appear in abnormal log data but with a different context, such as “Server startup failed,” then the appearance of these words might be considered abnormal because they shouldn’t appear in this context.
By using the MLM method, a BERT model can be trained to understand the contextual information of normal log data, enabling it to recognize abnormal contexts in abnormal log data, even when they structurally resemble normal log data. This helps improve the model’s performance in detecting abnormal log entries.
4.2 Problem Definition
Input Representation :
In the training phase, the existing log keys were replaced with the [MASK] token with a probability of 20%, while in the testing phase, each log key was replaced with the [MASK] token to generate test data.
Objective Function :

The objective function used for training …
4.3 LAnoBERT
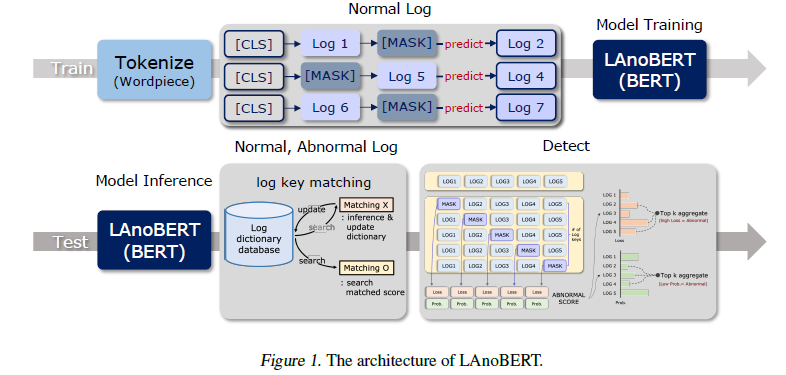
LAnoBERT proposed in this study can be largely divided into the following three parts: preprocessing, model training, and abnormal score computation.
PREPROCESSING
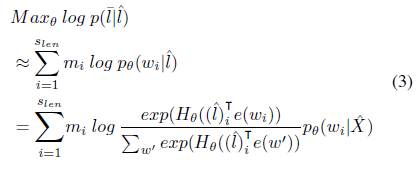
parser-free method (comparing) :
- Drain : the parts defined as a template are excluded and eliminated, whereas certain parts are replaced with 〈*〉.
- this study (regular expressions) : replaced the data with clear formats such as numbers, dates,
and IPs with the words ‘NUM’ or ‘IP
Preprocessed log sequences -> tokenized using the WordPiece -> BERT
MODEL
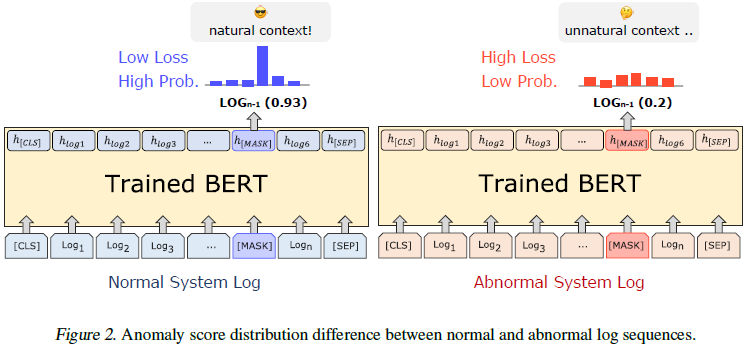
The most crucial assumption of this study is that “There is a difference between the context of a normal system log and that of an abnormal system log.”
explain : language models trained only with normal log will predict wrong when facing context of abnormal logs during the test.
prediction error’s defination : crossentropy loss that occurs between the label information and logit value generated when the model predicts [MASK] as a specific token
Train Phase : Training is initiated from scratch using the initialized BERT, and the same parameters as the BERT-base-uncased are used for the model. The training parameters are almost identical to those of the original BERT (Devlin et al., 2019); the only difference is that the masking probability is set to 0.2, training is only performed for normal logs.
Test Phase : All log keys present in the log sequence are applied with masking, and the predictive probability and error value are calculated.

ABNORMAL SCORE
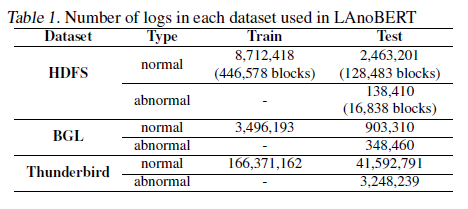
“Top-k aggregate” refers to the process in the test phase where, to compute an anomaly score for a given text log, the model calculates anomaly scores for all log keys and then selects only the top k highest anomaly scores to represent the overall anomaly level of the entire text log. This approach aims to reduce confusion because normal logs and abnormal logs typically share similar characteristics in most log keys, but only a very small number of log keys are crucial for identifying anomalies.
Specifically, for a given text log, the LAnoBERT model calculates an anomaly score for each log key during the test phase. These anomaly scores are then sorted, and the top k highest scores are chosen to represent the anomaly level of the entire text log. This approach allows for a more precise identification of the log keys that contribute to the anomaly without being influenced by other normal log keys. In this context, k is typically set to 5, indicating that the top five highest anomaly scores are selected to represent the overall anomaly situation of the text log.
In this study, k is set to 5.
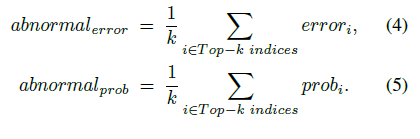
Top k values are selected from the set of calculated prediction errors and predictive probabilities to computer the final abnormal score.
Optimize training computational costs :
number of required computations becomes the total number of log sequences × the length of each log sequence.
- dictionary key is defined as a set of
- KEY = {key0, key1, key2,···,keyn}
- Each key has its corresponding abnormal_error and abnormal_prob as values
- DICT = {key1 : (abnormal_error, abnormal_prob),key2 : (abnormal_error, abnormal_prob),···,keyj : (abnormal_error, abnormal_prob)}
- if, input key matched to one of the log keys extracted as the abnormal score
- else, update dictionary
5. Experimental Setting
Datasets
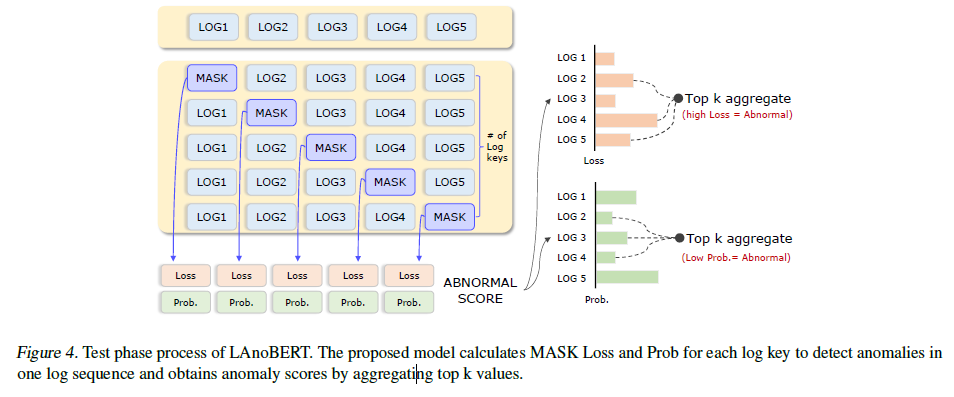
- HDFS (Hadoop Distributed File System): This dataset comprises log data generated in a private cloud environment. Each log contains multiple log sequences. The HDFS dataset is known for having a relatively simple architecture.
- BGL (Blue Gene/L Supercomputer): This dataset includes logs generated by the Blue Gene/L supercomputer. Each individual log sequence is labeled as normal or abnormal.
- Thunderbird: The Thunderbird dataset originates from the Thunderbird supercomputer system at Sandia National Laboratories. It includes alert and non-alert messages categorized by alert category tags. Among the three datasets, Thunderbird has the largest number of log messages.
Benchmark Methods
etc…
Evaluation Metrics
Evaluation Metrics : F1 score and AUROC(Area Under the Receiver Operating Characteristic Curve)
F1 equation :
The F1 score calculated using Eq. (6) is a metric influenced by the threshold of a model and cannot guarantee the reliability of the fundamental performance of an anomaly detection model; hence, AUROC, which is an evaluation metric unaffected by the threshold was also calculated.
6.Results
Anomaly Detection Performance
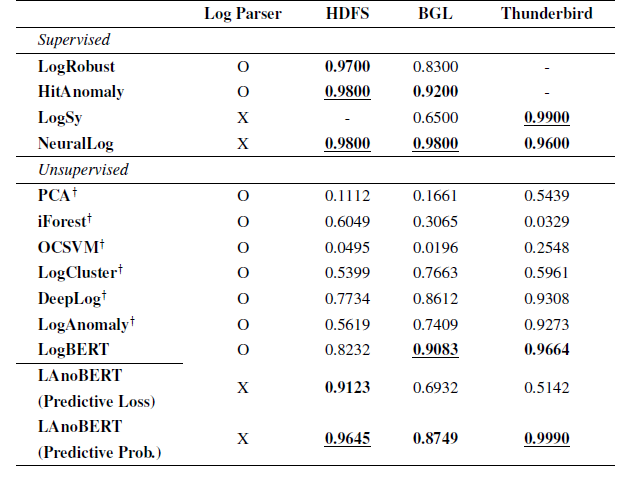
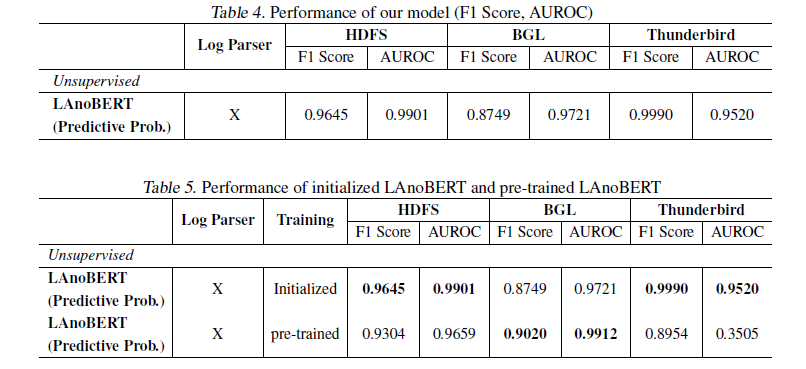
F1-score for the proposed LAnoBERT model and ten additional models :
unsupervised :
- all unsupervised models, except for the proposed LAnoBERT, were obtained from the LogBERT study
- BGL dataset was inferior compared to the HDFS dataset due to its more complex structure
- PCA, iForest, OCSVM, and LogCluster showed lower performance compared to DeepLog, LogAnomaly, and LogBERT which utilized deep learning techniques
supervised :
- LogRobust and HitAnomaly favorable on the HDFS and BGL datasets (Drain parser)
- LogSy uses classification model, good in Thunderbird , bad in BGL
etc…
Performance according to the BERT learning method
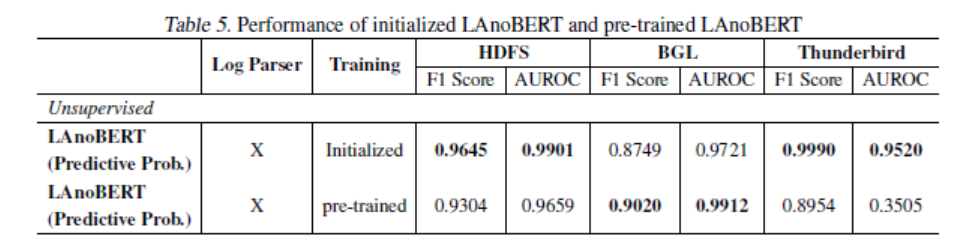
- BERT model pre-trained with natural language was used and model trained from scratch (Initialized) is showen in the chart
- F1 score in the BGL and Thunderbird data better in pre-trained model , F1 score in the HDFS data worse in pre-trained model
- reason 1 : HDFS data consisting of a very simple log structure have degraded performance
- reason 2 : BGL dataset is a more complicated dataset
- reason 3 : HDFS dataset after preprocessing is only 200, which is very few for expressing
- conclusion : the results demonstrate that incorporating the LAnoBERT framework with a pre-trained BERT model is aviable alternative
7.Conclusion
This study proposed LAnoBERT, which is an unsupervised learning-based system log anomaly detection model where a parser is not used. The proposed LAnoBERT learned the context of normal log data using MLM, and abnormal logs were detected based on the prediction error and predictive probability during the test. In terms of the nature of the system log, normal and abnormal data have similar characteristics; thus, a new score calculation method is proposed for defining the abnormal score based on the top-k predictive probability. The proposed model exhibited the best performance compared to the unsupervised models, and superior or similar performance compared to supervised learning based models. In addition, the efficient inference process proposed in this study is expected to work well in an actual system. Although the performances of benchmark models are heavily dependent on the use of log parser, our proposed LAnoBERT can be a robust and parser-independent log anomaly detection model.
future work :
- LAnoBERT requires individual training for each log dataset , to analysis log in different system.
- Transformerbased architecture incurs higher computational costs compared to RNN-based models due to its self-attention layer (O(n^2 · d) complexity) versus the recurrent layer of RNN (O(n · d^2) complexity) , parameter-efficient learning methods should be use
- Log Parser-free methodology can be improved by templating log sequences into the natural language via prompt tuning