No title
1 | title: TLS指纹综述 |
TLS指纹综述
一、ja3指纹综述
TLS指纹是利用TLS过程中的字段所得到的hash指纹,称为ja3,其项目已经于github开源:
- https://github.com/salesforce/ja3 被动检测获得TLS指纹
- https://github.com/salesforce/jarm 主动TLS指纹检测
然而,网络上普遍使用用于获取ja3指纹网址https://ja3er.com/form已经寄了,我们可以选用目前还在活跃的网址如下:https://tls.peet.ws/
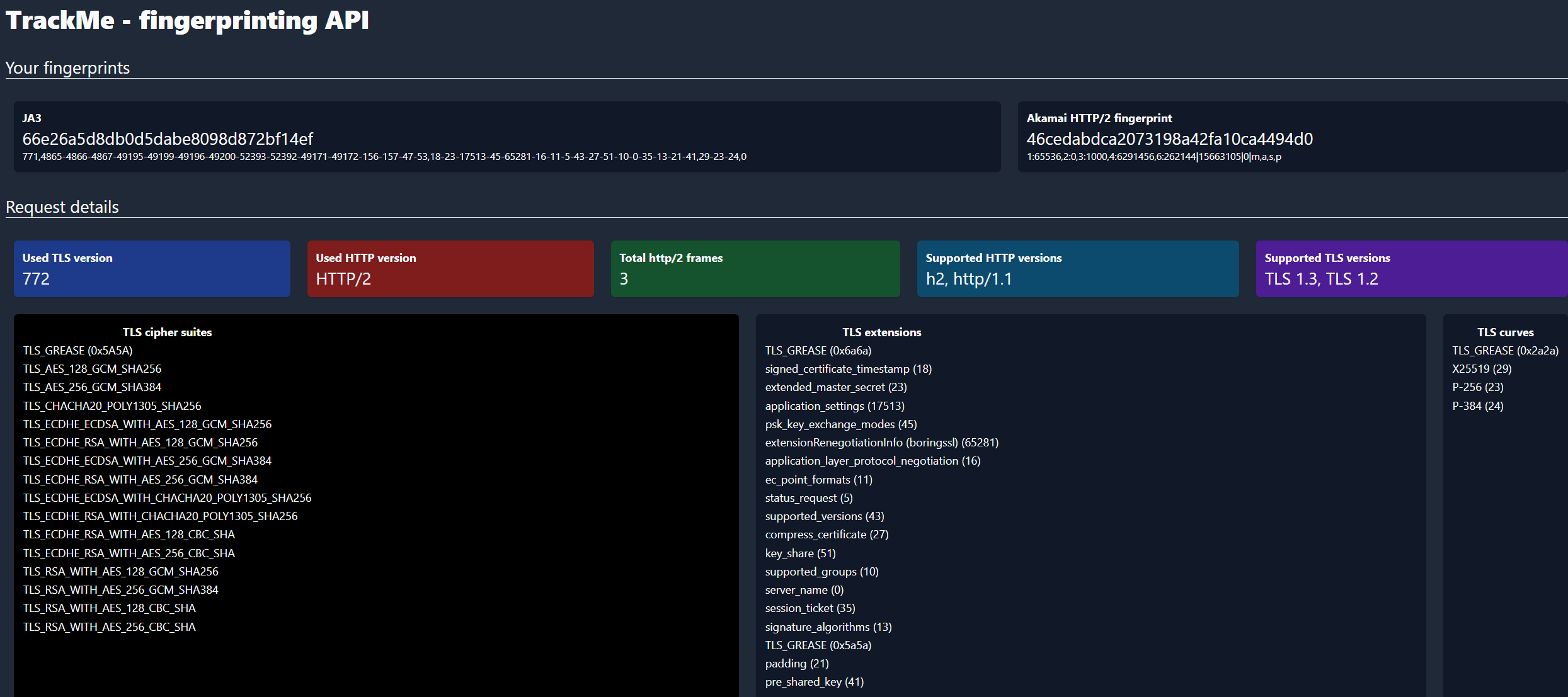
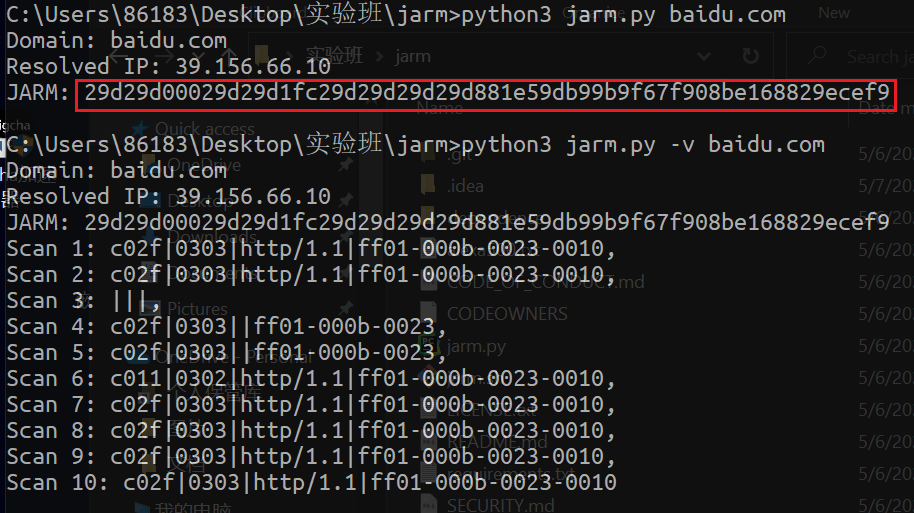
使用浏览器访问网址时,获取到本机的JA3指纹,这是从服务端对于用户端进行TLS指纹的探测,可以在某种程度上探测用户的操作系统、以及使用的浏览器版本。反之,通过jarm脚本,可以对于对应服务器的JARM,即ja3指纹进行探测,如下所示对百度进行探测。
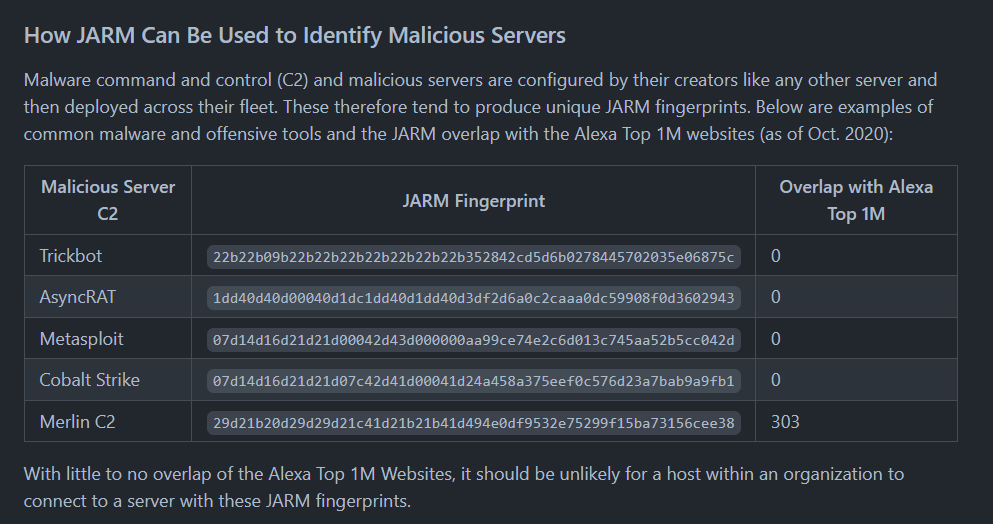
github官方仓库中提到,使用JARM可与i对于C2服务器进行识别,并列出了几种较为常见的渗透工具(病毒)C2服务器的JARM指纹,如下所示:
仓库中继续提到,当从 abuse.ch 编制的列表中扫描 Trickbot 恶意软件 C2 时,列表中 80% 的实时 IP 产生了相同的 JARM 指纹。将此 JARM 指纹与 Alexa 排名前 100 万的网站进行比较时,没有重叠。
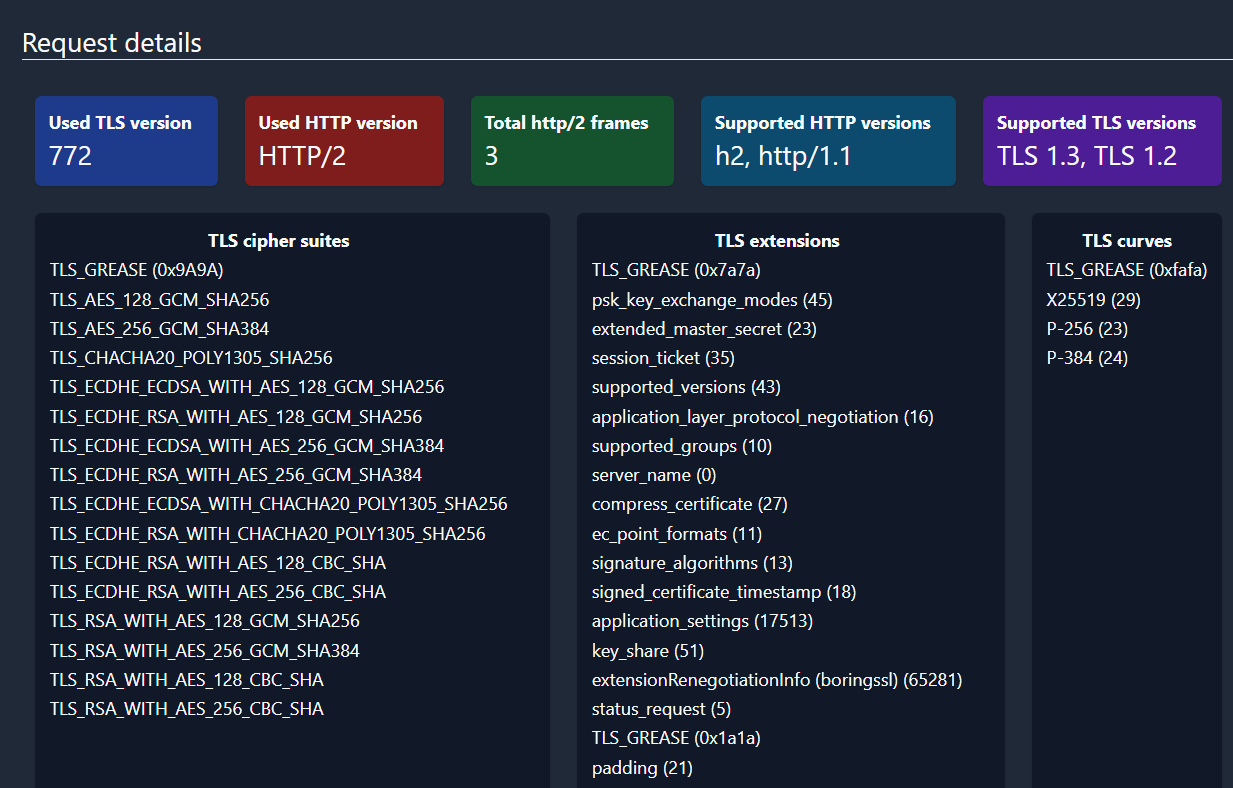
通过端口 443 扫描了整个互联网,数十亿个 IP,并发现了以下内容:
如果与 Cobalt Strike JARM 匹配的服务器在一年多的时间里属性没有变化,则更有可能是合法的误报,而与 2 个月前不存在的 Cobalt Strike JARM 匹配的服务器则更有可能是恶意的真阳性。
二、ja3&ja3s
ja3一般指的是所谓服务端的指纹信息;ja3s使用的
那么,JA3算法中的哈希值是如何得到的呢,通过本地的信息进行解释:
最终的JA3指纹:4558520b679631d89e69d41095530283
实际是由字符串:771,4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,11-43-16-45-23-13-10-65281-17513-0-27-18-35-51-5-21-41,29-23-24,0 进行md5得到的hash值。
后者可以分为五段,分别具有以下含义:
1 | TLSVersion:771 |
实际情况如下所示:

其中,可以看到随机插入的TLS_GREASE值,其定义如下:
GREASE是Generate Random Extensions And Sustain Extensibility的缩写,在RFC8701[2]中被正式定义,主要的用处是通过设计一种机制,来防止TLS协议在将来进行扩展的时候受到阻碍。
即,在TLS的字段中插入了一些无意义的值:
1 | {0x0A,0x0A}, {0x1A,0x1A}, {0x2A,0x2A}, {0x3A,0x3A}, {0x4A,0x4A}, {0x5A,0x5A}, {0x6A,0x6A}, {0x7A,0x7A}, {0x8A,0x8A}, {0x9A,0x9A}, {0xAA,0xAA}, {0xBA,0xBA}, {0xCA,0xCA}, {0xDA,0xDA}, {0xEA,0xEA}, {0xFA,0xFA} |
这些值可以由客户端在发送Client Hello时随机插入,通时,服务端必须忽略这些值。假设服务端的消息中出现了GREASE值,则客户端必须断开连接。说白了就是使得开发者们不那么懒惰,对生态进行维护。
知乎作者在文中这样写道:
以TLS为例,如果不通过GREASE对实现方式进行约束,软件逻辑有可能被实现为 CipherSuites,Extension 只支持目前协议中出现的值,如果发现了不在协议中的值就抛出异常。这样实现在当前版本的使用中不会碰到任何问题,但是如果IETF要对TLS协议进行升级,要引入更多CipherSuites值,那样当一个新版本TLS库与旧版本TLS库交互的时候,就会抛出异常,影响业务,这样新版本协议的部署就会遇到很大的阻碍。
回归到TLS指纹来讲,客户端的ja3在实际情况下的计算过程中,会被忽略掉(否则每一次的指纹就都不一样了)。
创建JA3之后,我们可以利用同样的方法对TLS握手的服务器端进行指纹识别,即对TLS Server Hello消息进行指纹识别,字段顺序如下:
1 | TLSVersion,Cipher,Extensions |
而后计算其hash值即可,那么,这个值有什么意义呢?
由于同一台服务器会根据Client Hello消息及其内容以不同的方式创建其Server Hello消息,因此无法通过一次应答的指纹标记服务器的身份。尽管服务器对不同的客户端的响应是不同的,他们对于同一个客户端的响应却总是一致的:

由上图,可以看到,使用a.py请求后,对待测指纹服务器进行请求多次,对应的Server指纹是不变的,如果更换请求端指纹,响应端指纹也会随之变化。也就是,在服务器和客户端都不变的情况下,会有一套对应的JA3、JA3s指纹对。
以github上开源的攻击框架pupy为例:
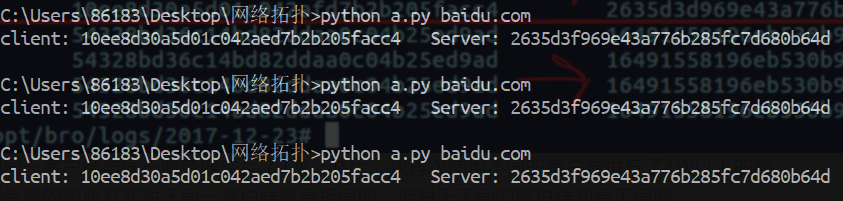
其加密算法被硬编码在ssl通信程序中,因此,其将会具有一个独一无二的Client hello中的Cipher Suites字段,即一个独一无二的JA3。此时,攻击者如果注意到了这一点,并尝试改变这一点,比如使用一些公共的库,或者系统套接字进行通信,则可以引入ja3s作为辅助:
由于C2服务器对该客户端应用程序的响应方式与Internet上的普通服务器对该套接字的响应方式相比来说是独一无二的,因此,如果我们结合JA3+JA3,那么我们就能够识别这种恶意通信:
- Metasploit Win10 至Kali:
- JA3=72a589da586844d7f0818ce684948eea -> JA3S=70999de61602be74d4b25185843bd18e
- Cobalt Strike Win10 至 Kali:
- JA3=72a589da586844d7f0818ce684948eea -> JA3S=b742b407517bac9536a77a7b0fee28e9
三、指纹的修改与随机化
1. 浏览器端对于TLS指纹的改动
一般来说,正常情况下的指纹应该是不变的,使用JA3算法就可以唯一的标识一台客户端主机,然而,在进行深入的测试中,发现了一些问题:


在Chrome 109版本(大概在2023年初开始计划实装此功能)后,TLS extensions变为随机顺序的字段,使得JA3的最终哈希值发生变化,经过查证,这一现象是被确认的:
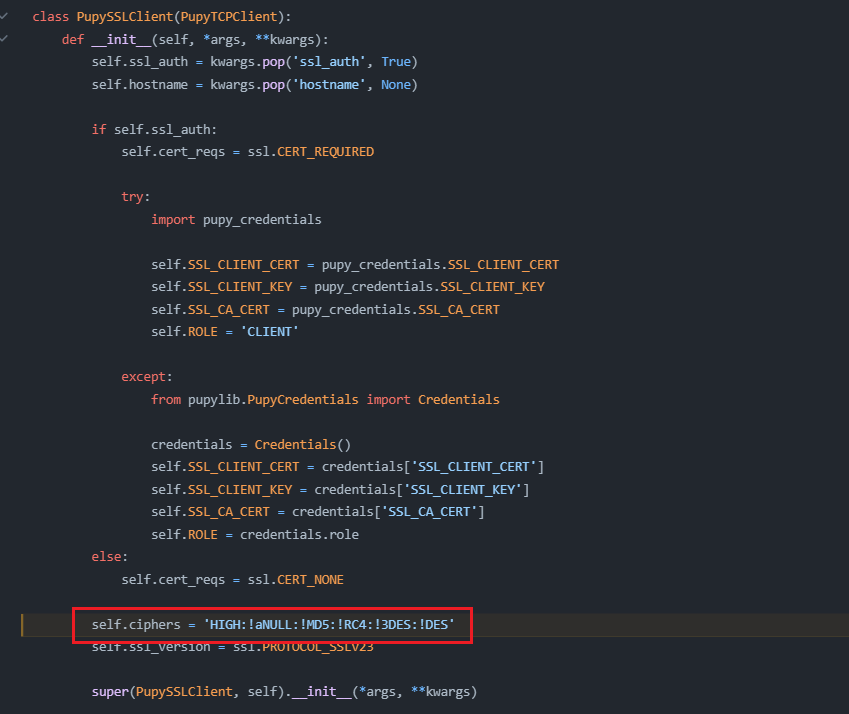
在这一更改的说明中提到,使用固定的拓展顺序,鼓励了服务器端针对chrome客户端的指纹识别。Chrome此举并不是为了防止TLS的指纹,而是为了增进TLS的生态…,告知内容链接如下:
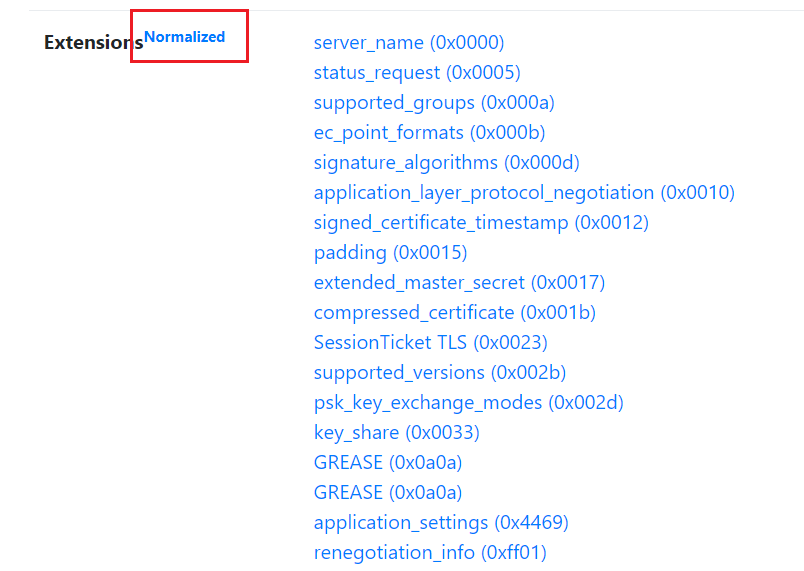
github对这个问题进行了讨论:https://github.com/net4people/bbs/issues/220,其中,有人指出,在专业进行TLS指纹检测的网址TLSFingerprint.io 中,其对于浏览器指纹迅速进行了Normalized(也就是排序)处理:
Normalized后的Chrome又具有了相同的指纹,但是存在两个问题:
- 丢弃字段顺序信息后,损失了大量的信息,哈希可能的最终值大大减少了;
- 不同TLS指纹监测站的标准亟待统一;
2. 使用脚本获得随机指纹
当然,由于每一次建立连接的就是客户端本身和服务器本身,其是可以对自己的TLS指纹进行伪装的,以下为github上开源的TLS指纹随机化项目:
https://github.com/netskopeoss/jarm_randomizer
其实现了27种JA3s指纹的随机化方式,项目中提到如下的可能进展:
1 | import os |
使用如上脚本进行JA3s脚本的学习,并伪装成对应服务器的JA3脚本。依然存在的问题是:不能够绕过大型网站对于自动化脚本的检查机制。
四、Network Protocol Fingerprinting (NPF)与排序
1. 其他指纹
- http指纹: https://lwthiker.com/networks/2022/06/17/http2-fingerprinting.html
- tcp指纹: https://en-academic.com/dic.nsf/enwiki/868408
- ssh指纹: https://engineering.salesforce.com/open-sourcing-hassh-abed3ae5044c/
网络中除了针对SSL/TLS协议可以进行如上的指纹进行探测,还可以对于多种,具有丰富可选配置的其他协议进行指纹的探测与记录工作,如上,列出了一些已有的,较为热门的指纹。
然而,一种指纹探测就使用一个程序来完成,始终缺少一个统一的规则集合,就像TLS指纹,多个指纹库要实现信息之间的同步,必须要对于指纹生成方式有一个统一的认知,这就是为什么我们需要NPF。
2.npf
npf被制定为一种针对网络中协议进行指纹提取的规则表示方法,下面以上文介绍过的TLS指纹进行简单的解释:
使用tls/1表示基于tls修正一次后的标准,如上图,区别在于使用了大括号表示排序,下文给出了Extension完整的定义:
1 | DEGREASE(x) = 0x0a0a if x is in TLS_GREASE, and x otherwise. |
实际上对于tls的定义就是一个类,然后,在实际情况下,任意对象可以使用如下语法嵌入这个类,如下图为修改前的tls某次消息的指纹对象:
1 | tls/ |
修改后的,如下所示,使用字典序进行了排序:
1 | tls/1/ |
下面是http、openvpn和tcp/ip协议的指纹定义:
1 | "http/" (method) (version) ((selected-header)*) |
通过npf规则约束,可以构建基于不同协议的指纹库,并指定对应的规则。
排序后的TLS指纹
排序带来的影响?
那么,排序是否影响了TLS的实际作用呢?即,进行排序后,到底对于TLS jarm指纹的影响有多大?

hnull的研究者提到,在源本包含2149个指纹种类的集合中,将tls进行排序后,指纹数量下降为2123个,即98.8%的指纹在排序后依然保持独立。
普遍采用随机化可能导致的安全问题?
- 给代码带了了复杂性(如心脏出血漏洞),并不关键
- 可能作为C&C消息通道,秘密传输盗窃信息
如下为元素数量,排列数,与能传输信息长度的关系
| n(元素数量) | ! _ (排列数) | lg( n !) (位数) |
|---|---|---|
| 5个 | 120 | 6.9 |
| 10 | 3628800 | 21.8 |
| 15 | 1307674368000 | 40.3 |
| 20 | 2432902008176640000 | 61.1 |
| 25 | 15511210043330985984000000 | 83.7 |
| 30 | 265252859812191058636308480000000 | 107.7 |
| 35 | 10333147966386144929666651337523200000000 | 132.9 |
Chrome 常见的 18 个 TLS 扩展的单个排列可以用作攻击者进行信息传输的通道,可以泄漏 lg(18!) = 52.5 位信息,这已经是一个非常大的数量了。假设其他ssl应用也跟随进行随机化,可能为攻击者提供新的信息通道。多次使用这一通道,可以泄露相当长的秘密信息,假设要传递的秘密信息是呈不自然序列的,可以先进行加密,而后在传递后解密;反之,假设秘密信息趋向于均匀随机,则可以直接进行传递。(这一安全问题建立在服务端有内鬼的假设上)
另一个问题是,服务端可能使用TLS随机化的方式对用户进行跟踪,如下,RFC提到,用户对于会话票据的重用可能会使用服务器跟踪用户。特别设计的随机化算法可以类似session一样标记用户。

https://hnull.org/2022/12/01/sorting-out-randomized-tls-fingerprints/#effectiveness