正则表达式简单笔记
正则表达式
python中可以通过import re引入re模块,用正则表达式处理字符串
一、正则表达式
在线正则表达式测试工具:https://regex101.com/
1、限定符
匹配单字符
? 限定符:通过used?可匹配use或used,等含有use字样,d可有可无;
*限定符:通过ab*c可以匹配 ac abc abbbbc等含有n个b,ac必须按照顺序有的字符串;
+限定符:即*限定符除去没有b的情况,ab不会被匹配;
{n}限定符:ab{6}c可匹配b出现次数为6的情况,或者,{2,6}为2-6次,{2,}为两次以上
匹配多字符
使用 **()**框选所要匹配的字符,然后正常使用限定符。
2、“或”运算符
正则表达式要匹配 acat或者 adog时,可以使用或运算符,表达式如下:
a(cat|dog)
3、字符类
[] 匹配符:
如果想匹配ab三个字母组成的内容,可以使用 [abc]+;
其中[]用于限制匹配的字符;
在方括号中,我们可以指定范围,语法如 [a-zA-Z]即大小写所有英文字符;
^匹配:
和方括号联用,[^0-9]+代表非数字
4、元字符
元字符是正则表达式预先定义好的内容
| 符号 | 释义 | 解释 |
|---|---|---|
| \d+ | 数字字符 | 等同于[0-9] |
| \w+ | 单词字符 | 英文、数字、下划线 |
| \s+ | 空白符 | TAB和换行符(空格) |
| \D+ | 非数字字符 | |
| \W+ | 非单词字符 | |
| \S+ | 非空白字符 | |
| \b | 单词边界 | \b的前一个字符和后一个字符不全是\w |
| .* | 任意字符 | 不包含换行符 |
注:
**+**为匹配多个连接的字符,而非一个一个单独匹配
| 特殊字符 | 释义 | 解释 |
|---|---|---|
| ^ | 匹配行首 | 如^a,只会匹配行首的a,而非所有a |
| $ | 匹配行尾 | 如$a,只会匹配行尾的a,而非所有a |
5、贪婪与懒惰匹配
正则表达式默认使用的是贪婪匹配;
即,当出现较大的字符能被一次匹配时,忽略其包含的较小的字符,优先匹配较大的字符,试举一例,当我们尝试匹配html标签,匹配内容如下:<span><b>this is a text</b></span>
我们可能会使用 <.+>进行匹配:
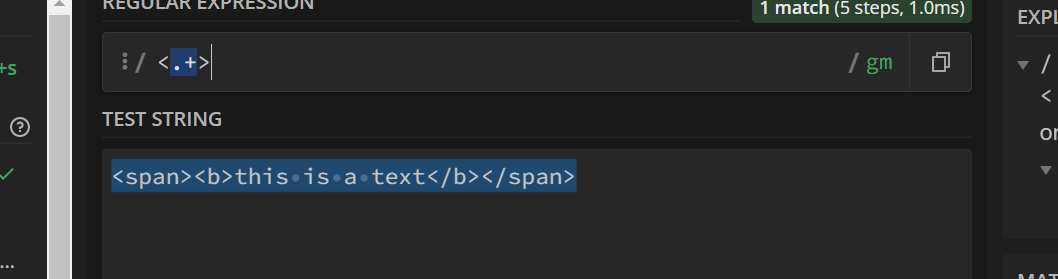
正则默认选择了最贪婪的匹配方法。
我们可以手动切换贪婪匹配为懒惰匹配,使用 <.+?>进行匹配: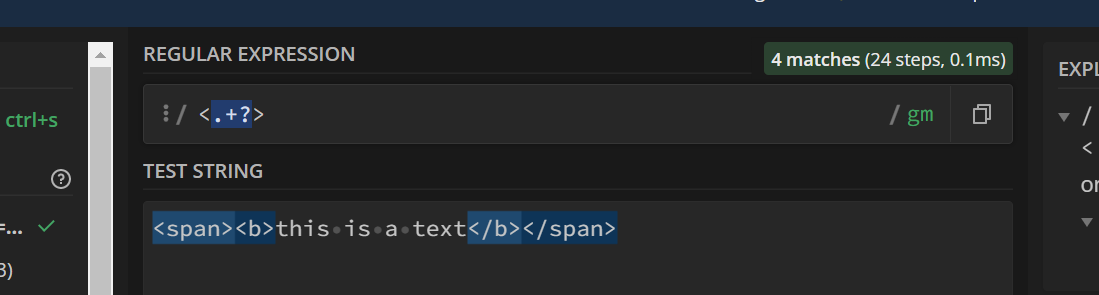
6、优秀教程
1 | [详细文本教程]: https://deerchao.cn/tutorials/regex/regex.htm "正则表达式30分钟入门教程" |
二、正则表达式的使用
1、. ^ $
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| a. | abacad | abacad | 匹配所有”a.”的字符 |
| ^a. | abacad | ab | 只从开头匹配”a.” |
| a.$ | abacad | ad | 只匹配结尾的”a.$” |
2、* + ? { }
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| a.? | abefacgad | ab ac ad | ?表示重复零次或一次,即只匹配”a”后面一个任意字符。 |
| a.* | abefacgad | abefacgad | *表示重复零次或多次,即匹配”a”后面0或多个任意字符。 |
| a.+ | abefacgad | abefacgad | +表示重复一次或多次,即只匹配”a”后面1个或多个任意字符。 |
| a.{1,2} | abefacgad | abe acg ad | {1,2}匹配1到2次任意字符。 |
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| a.*? | abefacgad | a a a | 惰性匹配 |
3、字符集[][^]
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| a[befcgd]* | abefacgad | abef acg ad | 表示匹配”a”后面[befcgd]的字符任意次` |
| a[^f]* | abefacgad | abe acgad | 表示匹配一个不是”f”的字符任意次 |
| [\d] | 412a3bc | 4 1 2 3 | 表示匹配任意一个数字,匹配到4个结果 |
| [\d]+ | 412a3bc | 412 3 | 表示匹配任意个数字,匹配到2个结果 |
4、分组 ()与 或 |[^]
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 | 110101198001017032 | 表示可以匹配一个正确的身份证号 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 | 1101011980010170 | 表示也可以匹配这串数字,但这并不是一个正确的身份证号码,它是一个16位的数字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 | False | 现在不会匹配错误的身份证号了()表示分组,将\d{2}[0-9x]分成一组,就可以整体约束他们出现的次数为0-1次 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 | 110105199812067023 | 表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14} |
5、转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的”\n”而不是”换行符”就需要对”"进行转义,变成’\‘。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次”\n”,字符串中要写成’\n’,那么正则里就要写成”\\n”,这样就太麻烦了。这个时候我们就用到了r’\n’这个概念,此时的正则是r’\n’就可以了。
| 正则 | 待匹配字符 | 匹配 结果 | 说明 |
|---|---|---|---|
| \n | \n | False | 因为在正则表达式中\是有特殊意义的字符,所以要匹配\n本身,用表达式\n无法匹配 |
| \n | \n | True | 转义\之后变成\,即可匹配 |
| “\\n” | ‘\n’ | True | 如果在python中,字符串中的’'也需要转义,所以每一个字符串’'又需要转义一次 |
| r’\n’ | r’\n’ | True | 在字符串之前加r,让整个字符串不转义 |
6、贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
|---|---|---|---|
| <.*> | Loading the Database |