关于编码方式的总结
各类编码总结
一、ascii、UTF-8、gbk
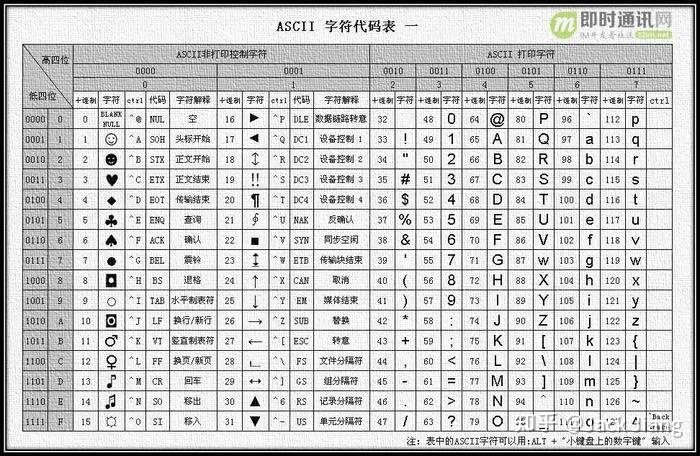
1、ascii码
ASCII 码一共规定了128个字符的编码:
2、UTF-8、UTF-16、UTF-32
utf(Unicode Transformation Format)
UTF-8:
utf-8是unicode的实现方法。其编码规则如下:
1)对于单字节的符号:字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的;
2)对于n字节的符号(n > 1):第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。

举例说明:
选择汉字“鲁”,在unicode官网查询其编码为U+9C81
转换为二级制数字即为:1001 1100 1000 0001,大小两字节。
根据上表,“鲁”字在第三个范围内,其表示即为1110xxxx 10xxxxxx 10xxxxxx,故将前文中的二进制数字填入,即为:11101001 10110010 10000001,再转换为十六进制,即为E9B281。
特征码:
BOM(byte order mark)
在较早的Windows环境下,系统为了能够识别UTF-8这一编码格式,为UTF-8添加了代表其格式的EF BB BF三位特征码(BOM),而后较高的Windows版本中,系统默认使用UTF-8这一编码格式,不再添加特征码(BOM)。经实验,若将XP环境下创建的、带有BOM的文件在Win10下打开,右下角会显示“带有BOM的UTF-8”字样,文件依然可以正常操作。
优点、缺点
缺点:
1. 英语国家用起来省空间,其他国家(语言)反而更费空间(汉字有可能需要三个字节)
2. 变长的储存方式导致执行索引效率低,有时需要转化为`UTF-16`或者`UTF-32`
优点:
1. 字符空间大于UTF-16;
2. 不存在大小端序;
3. 容错率高,容易检查出错误;
UTF-16:
即,使用两字节表示unicode的编码方法,有以下几个问题:
- 大小端序的设置容易导致乱码;
- 两字节只能表示六万多个字符,不够用;
- 容错低,一处出错,后面全错;
端序:
指字符按照什么顺序储存,与编码后内容一样即大端序,相反则小端序。
试举一例,一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?如果BOM是大端序,那么代码点就应该是594E,那么就是“奎”,如果BOM是小端序,那么代码点就应该是4E59,就是“乙”了。
UTF-32:
使用四字节表示Unicode的编码方式,占空间比较大。
特征码(附):
有编码对应的开头标志:
EF BB BF UTF-8 FE FF UTF-16/UCS-2, little endian FF FE UTF-16/UCS-2, big endian FF FE 00 00 UTF-32/UCS-4, little endian. 00 00 FE FF UTF-32/UCS-4, big-endian.
3、GBK/GB2312
GB全称GuoBiao国标,GBK全称GuoBiaoKuozhan国标扩展。GB18030编码兼容GBK,GBK兼容GB2312,其实这三种编码有着非常深厚的渊源,我们放在一起进行比较。 【GB2312】最早一版的中文编码,每个字占据2bytes。由于要和ASCII兼容,那这2bytes最高位不可以为0了(否则和ASCII会有冲突)。在GB2312中收录了6763个汉字以及682个特殊符号,已经囊括了生活中最常用的所有汉字。
总结来说,GBK就是两个字节组成的汉字字符集,同时其通过不让第一个字节为0的方式来兼容ascii码。实际上,有很多比较生僻的名字打不出来就是由于未被GB2312收录的原因。
全角&半角:
在GBK中,也收录了一些数字和字母,即ascii表中有的字母和数字,被GBK又收录了一遍。
那么,当我们直接使用ASCII码,用一个字节来表示数字和字母,就称之为半角;
若使用GBK中收录的那份数字和字母,用两个字节来表示数字和字母,就称之为全角;
通常我们使用半角,因为全角可能在编程过程中导致编译器不认识。
big5
big5是台湾搞出来的一种包括繁体的编码方式,与GBK不兼容。
GB18030
为了收录比GBK还多的汉字,使用四个字节来表示一个汉字,越来越复杂。
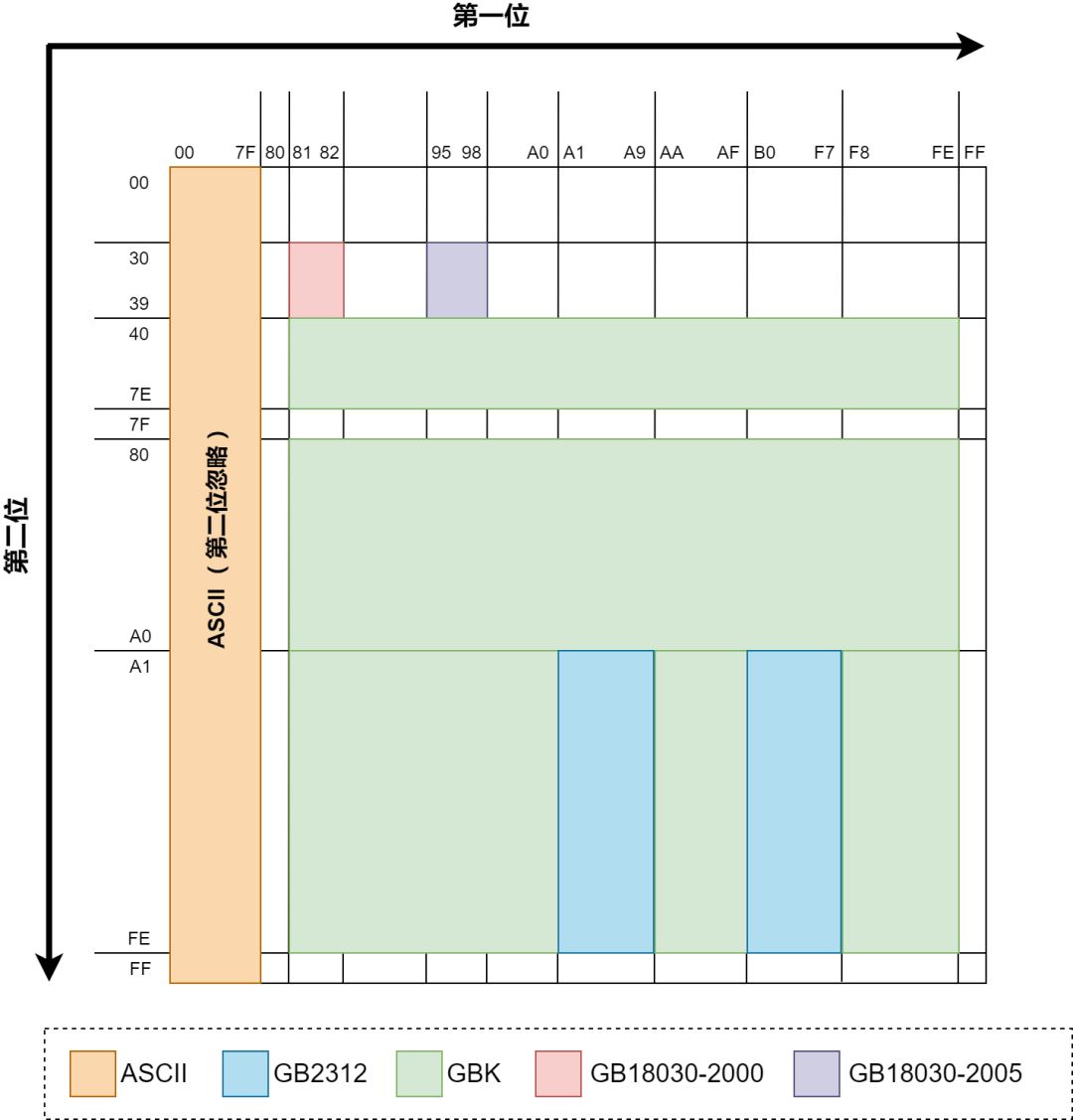
由于汉字编码方式不断迭代,迭代的同时又要保持兼容,GBK和GB2312比ASCII多出来的字都是2bytes,GB18030比GBK多出来的字都是4bytes,而ASCII、GB2312、GBK、GB18030直接有需要保持兼容性,最终就形成了被人诟病的国标汉字编码形式,具体可以参考下图:
二、乱码的来源
1、Unicode与国标的不兼容性
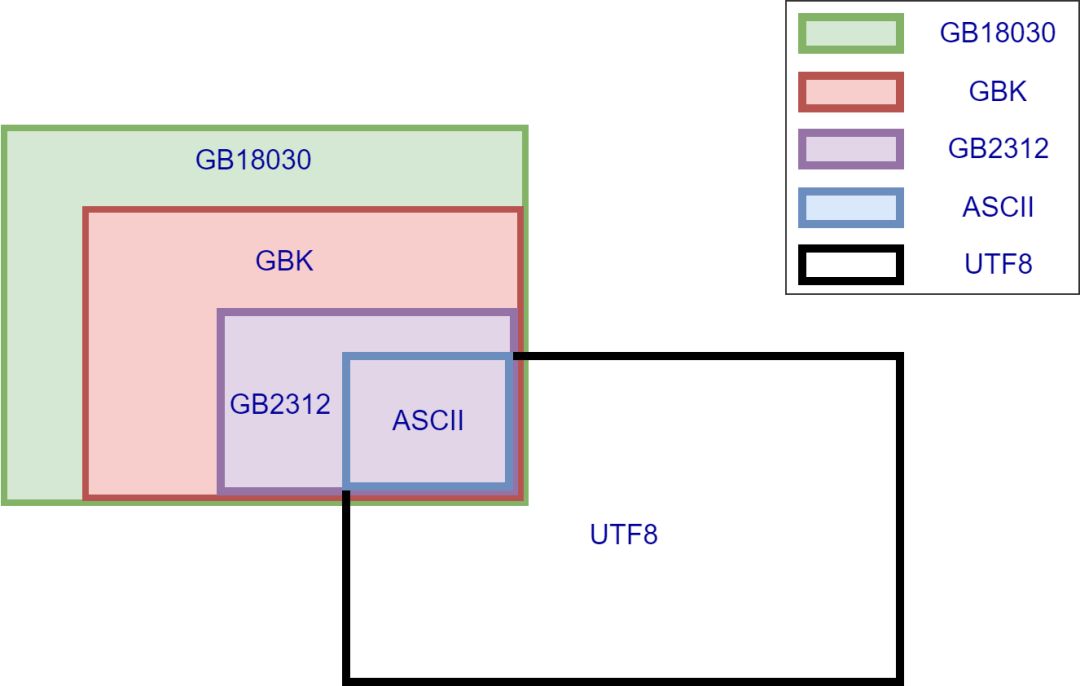
只兼容ASCII部分。
2、锟斤拷
虽然Unicode号称万国码,但是依然有未收录的字符,同时每个地区或操作系统对字符的支持程度也是不同的,因此在Unicode中就有一个特殊字符来代表未知字符:�
它的Unicode编码为0xFFFD。
将其Unicode编码转化为UTF-8后,十六进制表示为0xEF 0XBF 0XBD
若同时出现两个乱码符号,转化为十六进制就是0xEF 0XBF 0XBD 0xEF 0XBF 0XBD
这时候再将其强行转码为GBK编码,因为GBK中用两个字节表示一个字符,那么上述的字符就成了锟(0xEFBF),斤(0xBDEF),拷(0xBFBD)。
3、烫烫烫、屯屯屯、葺葺葺(qi四声)
Visual Studio中,未初始化的栈空间(即静态分配的空间)用0xCC填充,而未初始化的堆空间(即动态分配的空间)用0xCD填充。
而0xCCCC和0xCDCD在中文GB2312编码中分别对应“烫”字和“屯”字。
如果一个字符串没有结束符’\0’,输出时就会打印出未初始化的栈或堆空间的内容,这就是大名鼎鼎的“烫烫烫”、“屯屯屯”乱码。
而分配了,又被删除的内存,使用0xDDDD来填充,对应“葺”字。
三、base XX编码是什么
1、base 64、32、16编码流程
例如要被编码的字符串是:ILU
第一步:将
ILU字符串中的每一个字符转为对应于Ascii编码表的值,I = 73, L = 76, U = 85。第二步:将第一步中的
Ascii值分别转为对应的二进制格式,要求必须是造成8bit,不足8比特位高位补0。例如:1 的二进制是 1,明显不够8位,最终应该显示为:0000 0001。ILU的转化结果以下:73 = 01001001
76 = 01001100
85 = 01010101
第三步:根据
base X(这里的 X 表明 16,32,64等编号) 编码算法中所指定的y 个 bit 位为一个字符在表格中的下标的规则,对第2步的进行划分。例如base 16的规则要求,4位做为一个下标对应一个字符,即每4个位为一部分,故划分以下:第1部分:0100 是 (73 = 01001001,的前4个位)
第2部分:1001 是 (73 = 01001001,的后4个位)
第3部分:0100
第4部分:1100
第5部分:0101
第6部分:0101
第四步:将第三步中划分出的
每一个部分进行10进制转换,得出对应于10进制数的下标值,以下:0100 = 4,1001 = 9,4,12,5,5
第五步:最后一步,将第4步中得出的
下标数去查表,得出对应的字符,连在一块儿,就是编码结果
总结来说,对于16、32、64的base X编码,将内容转化为二进制,分别按4、5、6位分组,然后转化为字符形式即可,其中:
| 名称 | 下标数字的位个数 | 编码表字符串 | 位数不足是否会补全 = |
|---|---|---|---|
| base 16 | 4 | 数字0 |
不会,位数恰好是 4 的倍数 |
| base 32 | 5 | 大写字母A |
会 |
| base 64 | 6 | 大写字母A |
会 |
在编码后,base 16的字符数量会变为两倍;base 32会变为5/8倍;base 64会变为4/3倍。
2、对base 2^n 编码尝试进行计算
以字符串Lhl_2507为例:
以utf-8的形式编码为十六进制:4c686c5f32353037;
转化为二进制数:0100 1100 0110 1000 0110 1100 0101 1111 0011 0010 0011 0101 0011 0000 0011 0111;
然后分别按照4、5、6位分组:
其中base 16的结果就等同于utf-8的十六进制格式:4c686c5f32353037;
按照五位分组:01001 10001 10100 00110 11000 10111 11001 10010 00110 10100 11000 00011 0111
按照A~Z 2~7分别对应0~31(五位二进制转十进制),进行转化:JRUGYXZSGUYD为前十二位
最后一位需要补全,先补0变为二进制01110对应base 32中的O
为了与十六进制统一,需要补充=作为字符数量,前面5*4=20的组合有三组,最后多余一组,因此补充三个=
最终结果为JRUGYXZSGUYDO===
base 64与base 32思路相同
其64位数分别对应 A~Z a~z 0~9 + /用来对应0~63的十进制数
转化结果为TGhsXzI1MDc=
3、非2^n的base XX编码
base 58编码:
base58编码去掉了几个看起来会产生歧义的字符,如 0 (零), O (大写字母O), I (大写的字母i) and l (小写的字母L) ,和几个影响双击选择的字符,如/, +。结果字符集正好58个字符(包括9个数字,24个大写字母,25个小写字母)。
同时,由于58 不是2的整次幂,所以无法使用类似base64编码中使用直接截取3个字符转4个字符(3*8=4*6 , 2的6次方刚好64)的方法进行转换,而是采用我们数学上经常使用的进制转换方法——辗转相除法(本质上,base64编码是64进制,base58是58进制)。看下base58的编码表:
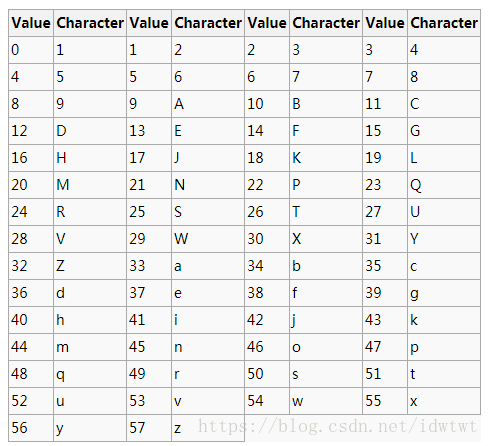
试举一例,若要将Lhl字符在utf-8编码下转化为base 58的形式:
转化为十六进制:4c686c
十六进制转十进制:5007468
十进制转58进制:辗转相除,然后将58进制数字转化为上表的表示形式即可。
结果为:E3QvX8qx
base 91编码:
base91是一种将二进制数据编码为ASCII字符的高级方法。它类似于uuencode或base64,但效率更高。base91产生的开销取决于输入数据。它的数量最多为23%(而base64为33%),其范围可以降低到14%,这通常发生在0字节块上。这使得base91在通过电子邮件或终端线路等二进制不安全连接传输较大文件时非常有用。
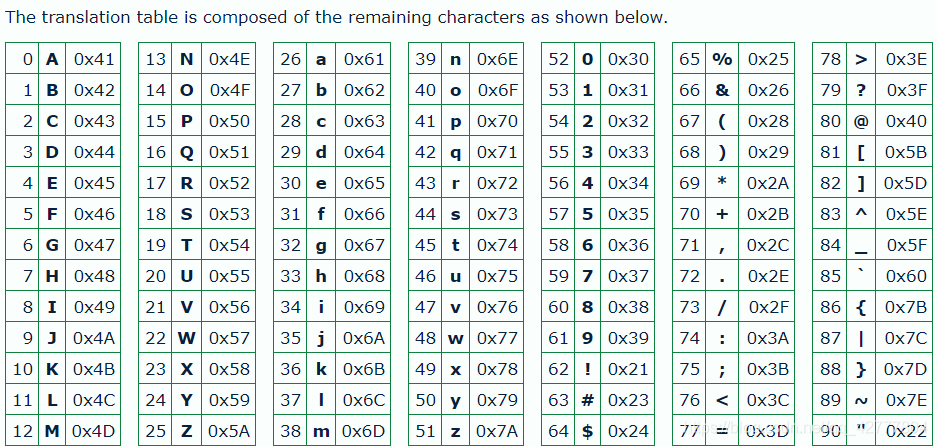
顾名思义,base91需要91个字符来表示用ASCII编码的二进制数据。在94个可打印的ASCII字符(0x21-0x7e)中,以下三个字符被省略以构建base91字母表:
-(破折号,0x2d)
\(反斜杠,0x5C)
‘(撇号,0x27)
翻译表由如下所示的其余字符组成。
引用(参考):
1 | [01]: http://www.hiencode.com/ "站长工具,用于转化编码" |